




This is a summary of chapter 1 of the Introduction to Statistical Learning textbook. I’ve written a 10-part guide that covers the entire book. The guide can be read at my website, or here at Hashnode. Subscribe to stay up to date on my latest Data Science & Engineering guides!
Overview of Statistical Learning
Statistical learning simply refers to the broad set of tools that are available for understanding data. There are two main types of statistical learning: supervised and unsupervised.
Supervised Learning
Supervised learning involves building statistical models to predict outputs (Y) from inputs (X). For example, assume that we have a salary dataset for statisticians. The dataset consists of the experience level and salary for 10 different statisticians.
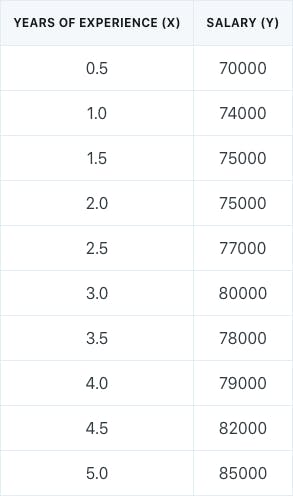
We could build a simple linear regression model to predict the salary of statisticians by using experience level as a predictor. This is an example of supervised learning, where we have supervising outputs (salary values) that guide us in developing a statistical model to determine the relationship between experience level and salary.
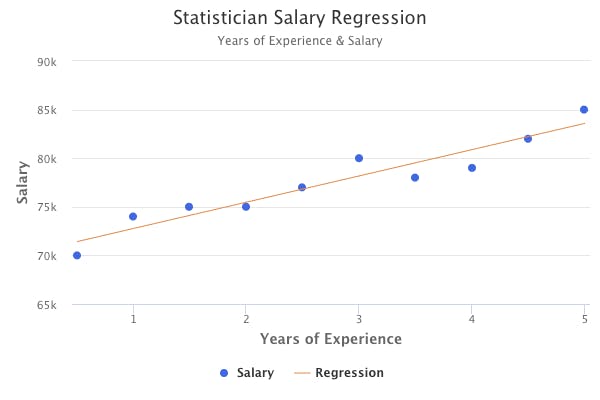
In general, there are two main types of supervised learning: regression and classification.
Regression
Predicting a quantitative output is known as a regression problem. For example, predicting someone’s salary is a regression problem.
Classification
Predicting a qualitative output is known as a classification problem. For example, predicting whether a stock will go up or down is a classification problem.
Unsupervised Learning
Unsupervised learning involves building statistical models to determine relationships from inputs (X). There are no supervising outputs. For example, assume that we have a customer dataset. The dataset consists of the annual salary and annual spend on Amazon for 10 different individuals.
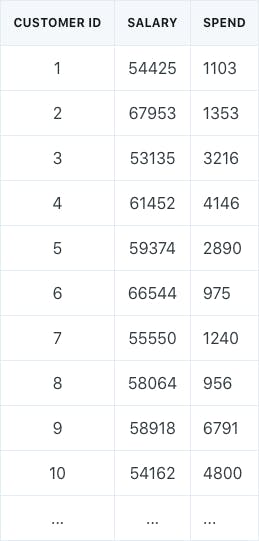
We could use a statistical clustering algorithm to group customers by their purchasing behavior. This is an example of unsupervised learning, where we do not have supervising outputs that already inform us which customers are low spenders, average spenders, or high spenders. Instead, we have to come up with the determination ourselves.
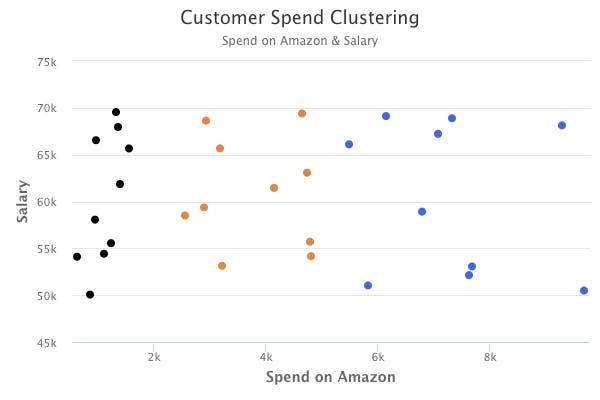
In general, there are two main types of unsupervised learning: clustering and association.
Clustering
Determining groupings is known as a clustering problem. For example, grouping customers together based on purchasing behavior is a clustering problem.
Association
Determining rules that describe large portions of a dataset is known as an association problem. For example, determining that people who buy X also buy Y is an association problem. A modern real-world example of this is Amazon’s “frequently bought together” product recommendations.
Originally published at https://www.bijenpatel.com on August 1, 2020.